Missed alerts turn into outages, outages turn into lost revenue. ExterNetworks Inc. delivers 24/7 NOC & Help Desk support to keep everything running smoothly.
Get 24/7 IT Support NowEvery organization operates on a fundamental premise: the data driving decisions must be trustworthy. Yet, across industries, compromised information costs businesses an average of $15 million annually in the form of bad decisions, regulatory penalties, and operational failures. Data integrity represents the cornerstone of reliable information systems—ensuring that data remains accurate, consistent, complete, and unaltered throughout its entire lifecycle.
At its core, data integrity encompasses both the physical protection of information and the logical validation of its content. Physical integrity safeguards data from hardware failures, power outages, and natural disasters. Logical integrity maintains accuracy through rules, constraints, and relationships within databases. According to Harvard Business School, organizations with strong integrity frameworks reduce data-related errors by up to 80%.
The concept extends beyond technical definitions. Consider a hospital’s patient records: a single corrupted medication dosage could prove fatal. Financial institutions face similar stakes—one misplaced decimal in transaction data can trigger cascading compliance violations. Modern network environments depend on continuous data validation to maintain system reliability.
What makes data integrity particularly crucial today? The exponential growth of data—expected to reach 175 zettabytes by 2025—amplifies the consequences of corruption. Organizations can no longer treat data quality as an afterthought.
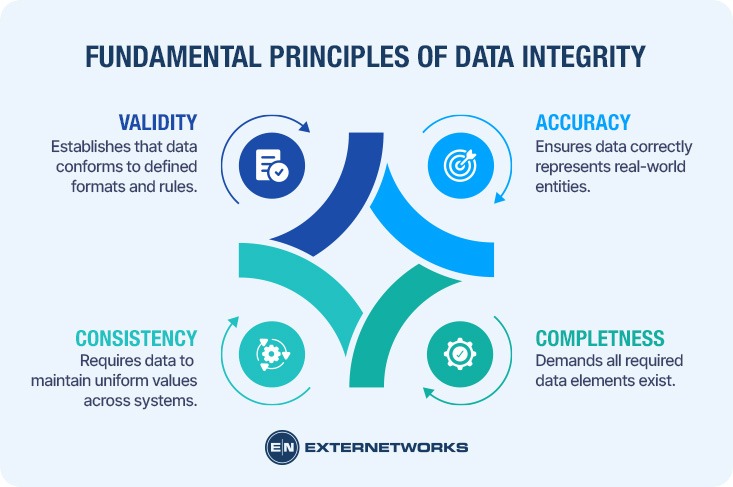
At its core, what is data integrity if not the adherence to fundamental principles that govern how information maintains its value throughout its lifecycle? Data integrity rests on four foundational pillars that determine whether organizational data can be trusted for critical operations.
Accuracy ensures that data correctly represents the real-world entities or events it describes. A customer address must match their actual location; a transaction timestamp must reflect when the exchange occurred. Without accuracy, every downstream decision becomes suspect.
Completeness demands that all required data elements exist within their appropriate context. Missing fields—whether a purchase order number or a product specification—create gaps that compromise analytical validity and operational execution.
Consistency requires data to maintain uniform values across all systems where it appears. According to research, when customer information differs between sales and support databases, the inconsistency undermines both customer experience and business intelligence.
Validity establishes that data conforms to defined formats, ranges, and business rules. An email address must contain an “@” symbol; a date must exist on the calendar; inventory counts cannot be negative. These constraints, when properly enforced across network environments, prevent invalid data from corrupting databases and triggering cascading errors throughout interconnected systems.
Maintaining data integrity requires a multi-layered approach that addresses both technical safeguards and operational protocols. The data integrity definition encompasses not just the concept itself but the active measures organizations implement to preserve accuracy and consistency.
Technical controls form the foundation. Database systems employ validation rules and constraints that automatically reject improperly formatted entries—whether that’s enforcing unique identifiers, verifying data types, or maintaining referential relationships between tables. Checksums and hash functions detect unauthorized modifications by creating digital fingerprints of data that change when content is altered.
Access controls determine who can view, modify, or delete information. Implementing appropriate access permissions prevents unauthorized changes while reducing accidental errors. Regular backups create recovery points when data privacy and integrity face threats from system failures or security breaches.
However, technology alone proves insufficient. Organizations must establish clear data governance policies—standardized procedures for data entry, modification workflows requiring approval, and regular integrity audits that identify inconsistencies before they cascade through systems. Training staff on these protocols ensures human actions align with technical safeguards.
While often used interchangeably, data integrity and data quality represent distinct but complementary concepts. Understanding the meaning of data integrity requires recognizing how it differs from quality metrics. Data quality focuses on the fitness of data for its intended purpose—attributes like accuracy, completeness, timeliness, and relevance to business objectives. What is Data Integrity? | IBM explains that quality measures whether data meets user expectations.
Data integrity, however, operates at a more fundamental level. It ensures data remains unaltered and trustworthy throughout its lifecycle, regardless of its quality. A dataset can maintain perfect integrity—unchanged from its original state—while still containing inaccurate or outdated information. Conversely, high-quality data loses all value if its integrity becomes compromised through unauthorized modifications or system errors.
The relationship is hierarchical: integrity provides the foundation upon which quality is built. Without integrity guarantees, organizations cannot trust their quality metrics. What Is Data Integrity? | Salesforce emphasizes that integrity focuses on structural consistency—maintaining relationships, formats, and constraints—while quality addresses content appropriateness. Both remain essential, yet integrity serves as the non-negotiable baseline for any reliable data ecosystem.
Understanding the importance of data integrity begins with recognizing the vulnerabilities that threaten it. Data faces numerous risks throughout its lifecycle, from creation through processing, storage, and eventual deletion. According to IBM, threats to data integrity fall into two primary categories: human-induced errors and system-level vulnerabilities.
Human error remains the leading cause of integrity failures. Simple mistakes during data entry, improper handling during transfers, or accidental deletions can corrupt entire datasets. Salesforce research indicates that human-related data quality issues cost U.S. businesses approximately $3.1 trillion annually, underscoring the financial impact of these seemingly minor mistakes.
System-level threats present equally serious challenges. Malware and cyberattacks specifically target data modification, inserting false records or corrupting existing information. Hardware failures—from disk crashes to network disruptions—can introduce errors during data transmission or storage. SentinelOne highlights that ransomware attacks increasingly focus on compromising data integrity rather than just availability, making detection more difficult.
Environmental factors compound these risks. Power outages during write operations, inadequate data security measures, and poorly configured backup systems can all introduce inconsistencies. Organizations must address these multifaceted threats through comprehensive protective strategies that anticipate both technical failures and human vulnerabilities.
Understanding data integrity becomes clearer when examining real-world scenarios where it fails. Consider a healthcare organization where patient medication records become corrupted during a system migration. A decimal point shifts in dosage information, transforming 0.5mg into 5mg—a tenfold error that could prove fatal. This scenario demonstrates how seemingly minor technical failures cascade into life-threatening consequences when data quality deteriorates.
In financial services, imagine an accounting system that fails to enforce referential integrity constraints. When a customer record is deleted without removing associated transaction data, orphaned records accumulate. Over time, unauthorized access attempts to these fragmented records create security vulnerabilities, while financial reconciliations produce inconsistent totals. According to AWS research, such integrity violations often remain undetected until audit failures or compliance reviews expose them.
E-commerce platforms face unique challenges when inventory systems lack proper validation. A common pattern involves concurrent transactions updating the same product quantity without proper locking mechanisms. Two customers simultaneously purchase the last item in stock, both receive order confirmations, but only one item exists—creating customer service nightmares and reputational damage that extends far beyond the initial technical failure.
Protecting data accuracy requires implementing comprehensive strategies across technical, procedural, and organizational dimensions. Organizations must establish multiple defensive layers that address vulnerabilities throughout the data lifecycle.
Implement validation rules at data entry points to prevent incorrect information from entering systems. Input validation verifies that data matches expected formats, ranges, and types before acceptance. Automated checks catch formatting errors, duplicate entries, and missing required fields immediately—preventing contamination at the source. Checksums and hash functions verify data hasn’t been altered during transmission or storage, providing mathematical proof of integrity.
Restricting data access through role-based access controls ensures only authorized personnel can modify sensitive information. Granular permissions prevent unauthorized alterations while maintaining an audit trail of all changes. Regular access reviews identify and revoke unnecessary permissions, minimizing exposure to internal threats.
Regular backups create restoration points if data becomes corrupted. However, backups themselves require integrity verification—corrupted backups provide false security. Testing recovery procedures ensures backups function correctly when needed, transforming theoretical protection into practical resilience. Understanding these protective measures sets the foundation for examining the technical mechanisms that verify data remains unchanged.
At the core of modern data integrity verification lie two fundamental cryptographic techniques: checksums and hash functions. These mathematical tools transform data into fixed-size values that serve as digital fingerprints, enabling systems to detect even single-bit alterations. A checksum applies an algorithm to generate a numerical value representing the data’s state, while hash functions produce more sophisticated cryptographic representations using algorithms such as SHA-256 or MD5.
Hash functions operate through one-way mathematical transformations that convert input data of any size into a fixed-length output string. When data transfers between systems—whether across network infrastructure or storage tiers—the receiving system recalculates the hash and compares it against the original value. Any discrepancy signals corruption or tampering. This mechanism proves particularly valuable for maintaining data consistency across distributed environments where information replicates across multiple locations.
Checksums offer simpler validation through additive or CRC (cyclic redundancy check) methods. While less computationally intensive than hash functions, they provide effective error detection for routine data transfers. Modern integrity systems often combine both approaches: checksums for quick validation during routine operations and cryptographic hashes for security-critical scenarios where detecting intentional manipulation matters most. This layered verification strategy balances computational efficiency with robust protection against both accidental corruption and malicious interference.
While robust data integrity frameworks provide substantial protection, organizations must recognize inherent limitations in any integrity system. No technical solution can guarantee absolute protection against all threats—determined adversaries with sufficient resources may eventually compromise systems —and human error remains a persistent vulnerability that technology alone cannot eliminate.
Data completeness presents particular challenges in distributed environments where information flows through multiple systems and organizational boundaries. According to Improvado, incomplete data often stems from integration failures between disparate platforms, inadequate validation rules, or poor monitoring infrastructure that fails to detect missing records. Organizations must balance the cost of comprehensive integrity controls against operational efficiency—excessive validation can slow transaction processing and create user friction.
However, regulatory compliance requirements often dictate minimum integrity standards regardless of cost considerations. The complexity of modern data ecosystems means verification blind spots inevitably exist, particularly at integration points between legacy systems and cloud infrastructure. Organizations should conduct regular integrity assessments to identify these gaps and implement risk-based mitigation strategies rather than pursuing unattainable perfection.
Data integrity goes far beyond technical accuracy—it forms the foundation of organizational trust and operational effectiveness. Organizations that maintain rigorous integrity standards protect themselves from financial losses, compliance violations, and reputational damage that can take years to rebuild. As data volumes continue expanding exponentially, the complexity of maintaining integrity across distributed systems, cloud environments, and real-time processing pipelines increases proportionally.
Successful implementation requires balanced investment across technical controls, operational oversight frameworks, and human training initiatives. While cryptographic methods like hashing and checksums provide robust mathematical verification, they cannot substitute for comprehensive data governance policies that define ownership, access protocols, and validation procedures. According to industry research, organizations with mature governance frameworks experience significantly fewer data quality incidents and faster recovery when problems occur.
The most critical insight remains straightforward: data integrity is not a one-time achievement but an ongoing commitment requiring constant vigilance, adaptation to emerging threats, and organizational alignment around shared standards of excellence.
Maintaining data integrity requires drawing on authoritative sources that span technical implementation, security frameworks, and compliance standards. The foundational concepts explored throughout this guide reflect industry consensus documented by leading technology organizations and standards bodies.
Primary technical guidance comes from IBM’s comprehensive data integrity framework, which establishes core principles for accuracy, consistency, and reliability. Business applications and database integrity considerations receive detailed treatment in Salesforce’s data integrity documentation, particularly regarding customer relationship management systems. Security-focused perspectives appear in Rapid7’s threat analysis and SentinelOne’s cybersecurity framework.
Operational implementations benefit from Splunk’s practical guidance on monitoring and validation, while AWS addresses cloud-specific integrity challenges. Academic perspectives and business impact analysis are drawn from Harvard Business School Online, examining the organizational consequences of integrity failures.
Formal definitions and compliance standards reference NIST’s official glossary, which provides authoritative terminology used across government and industry sectors. These sources collectively establish the evidence-based framework essential for implementing effective data integrity programs that protect organizational assets while enabling operational excellence.
See how ExterNetworks can help you with Managed NOC Services
Contact Us



