Introduction: The Imperative for IT Transformation
In today’s digital-first economy, the performance of IT infrastructure is directly tied to business success. A seamless user experience, unwavering uptime, and the ability to innovate at speed are no longer competitive advantages—they are baseline expectations.
However, the very technology driving this progress has created a crisis for the teams tasked with managing it.

The explosion of data, the rise of hybrid clouds, microservices, and IoT devices has pushed the complexity of modern networks beyond the limits of human-scale management. This new reality demands a fundamental shift in how we approach IT operations, setting the stage for a critical evaluation of established practices versus transformative new technologies.
The Evolving IT Landscape: Complexity and Demands
Modern IT infrastructure is a dynamic, distributed ecosystem. Unlike the monolithic, on-premise environments of the past, today’s networks are a complex tapestry of physical hardware, virtual machines, containers, and cloud services. This heterogeneity generates an unprecedented volume and variety of operational data—logs, metrics, and traces—from thousands of sources.
Simultaneously, business demands have intensified. Any amount of downtime or latency can directly impact revenue, erode customer trust, and damage brand reputation. Meeting stringent Service Level Agreements (SLAs) is no longer a goal; it’s a necessity.
The Crisis of Traditional IT Operations: Alert Fatigue and Reactive Stances
The traditional model for managing this complexity —the Network Operations Center (NOC) —is struggling under the strain. NOC teams are inundated with a constant stream of alerts from disparate monitoring tools.
This “alert storm” creates a high noise-to-signal ratio, where critical warnings are often lost in a sea of irrelevant notifications. The result is alert fatigue, where engineers become desensitized to warnings, leading to slower incident response times. This model forces IT operations into a perpetually reactive posture, constantly firefighting issues after they have already impacted the customer.
AIOps vs. Traditional NOC: Setting the Stage for Transformation
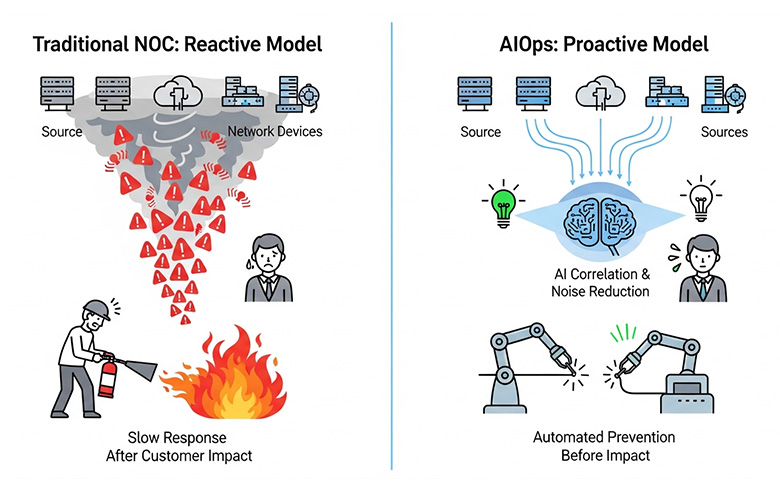
This is the central conflict for modern IT leaders: clinging to a familiar but failing reactive model or embracing a new, proactive paradigm. The traditional NOC represents the old guard—a human-centric approach that relies on manual processes and siloed knowledge.
In contrast, AIOps (Artificial Intelligence for IT Operations) represents the future—an intelligence-driven approach that leverages Machine Learning and automation to predict, detect, and resolve issues at machine speed.
This guide provides a definitive comparison, exploring the strengths and weaknesses of each approach to illuminate the path toward genuine IT transformation.
The Traditional Network Operations Center (NOC): Strengths, Weaknesses, and the Status Quo
For decades, the traditional Network Operations Center (NOC) has been the central nervous system of IT operations. Staffed by skilled engineers, its primary mission is to ensure the health, availability, and performance of the IT infrastructure. This model established the foundational practices of network management, but its core design is increasingly misaligned with the demands of the digital era.
Core Functions of a Traditional NOC
The work of a traditional NOC revolves around a well-defined set of reactive tasks. Engineers use a suite of monitoring tools to watch over networks, servers, and applications. When a predefined threshold is breached, an alert is generated. This triggers an incident response process that typically involves creating a ticket in an IT Service Management (ITSM) system, manually investigating the issue by consulting various dashboards and logs, and attempting to resolve it. Playbooks govern the entire workflow and rely heavily on the experience and intuition of the human operators.
The Reactive Cycle: Limitations and Pain Points
The fundamental limitation of the traditional NOC is its reactive nature. It is designed to respond to problems, not prevent them. This leads to several critical pain points:
- Slow Root Cause Analysis (RCA): Without a unified view, engineers must manually correlate data across siloed tools, making RCA a time-consuming detective exercise.
- High Mean Time to Resolution (MTTR): Manual processes for detection, ticketing, investigation, and resolution inherently introduce delays, prolonging downtime.
- Inability to Scale: As infrastructure complexity grows, the volume of alerts and potential failure points overwhelms human capacity, making it impossible to scale operations effectively.
- Business Impact: Prolonged outages or performance degradation directly affect the user experience, jeopardize SLAs, and result in significant financial losses.
Introducing AIOps: A Paradigm Shift for IT Operations
AIOps is not merely an enhancement to the traditional NOC; it is a complete reimagining of how IT operations function. By applying AI technologies to the vast streams of operational data, AIOps platforms introduce a layer of intelligence that automates and accelerates processes that were previously manual, slow, and prone to error.
What is AIOps? Defining the Intelligence Layer
AIOps, or Artificial Intelligence for IT Operations, refers to multi-layered technology platforms that automate and enhance IT operations through analytics and Machine Learning (ML). It acts as an intelligent aggregator, ingesting data from every corner of the IT infrastructure—from network devices and servers to applications and cloud services. By applying advanced algorithms to this consolidated data set, AIOps can identify patterns, predict future events, and pinpoint the root cause of issues with a speed and accuracy that human teams cannot match.
Core Principles of AIOps: Data-Driven, Proactive, and Automated
The AIOps paradigm is built on three transformative principles:
- Data-Driven: AIOps replaces human intuition and guesswork with decisions based on comprehensive data analysis. It correlates disparate data sources to build a complete, context-rich picture of the IT environment.
- Proactive: Instead of waiting for systems to fail, AIOps uses predictive analytics and anomaly detection to identify potential issues before they escalate into service-impacting incidents. This shifts network management from firefighting to proactive prevention.
- Automated: AIOps automates routine and complex tasks, from alert correlation and root-cause analysis to ticket creation and remediation. This frees human engineers to focus on higher-value strategic initiatives.
The AIOps Data Foundation: Ingestion, Analysis, and Insight
The power of any AIOps solution lies in its data foundation. Effective platforms must be able to ingest massive volumes of diverse data in real time, including logs, metrics, events, and ticketing data from existing monitoring tools. Once ingested, this data is processed using a variety of Machine Learning techniques to perform analysis. This includes anomaly detection to spot deviations from normal behavior, event correlation to group related alerts, and predictive modeling to forecast future performance, ultimately generating actionable insights rather than raw data.
AIOps Capabilities in Action: Driving Proactive and Predictive Operations
The true value of AIOps is realized when its core principles are applied to address the most pressing challenges in IT operations. By infusing intelligence into key workflows, AIOps transforms the day-to-day reality of managing complex IT infrastructure.
Intelligent Alert Management and Noise Reduction
In a traditional NOC, engineers face a constant barrage of alerts, many of which are redundant or low-priority. AIOps tackles this problem head-on by ingesting alerts from all monitoring tools and using algorithms to correlate them. It automatically groups related alerts into a single, context-rich incident, filtering out the noise and dramatically reducing the overall volume. This ensures engineers focus only on what truly matters, eliminating alert fatigue and accelerating incident response.
Accelerated Incident Detection and Root Cause Analysis (RCA)
When an incident does occur, speed is critical. AIOps automates the discovery and diagnosis process. By analyzing real-time and historical data, the platform can identify the precise root cause of an issue in minutes, rather than the hours or days it might take a human team. It presents a clear narrative of what happened, why it happened, and what systems are affected, providing engineers with the information they need to resolve the problem quickly and effectively.
Enhanced Network Performance and Reliability
AIOps moves beyond simple up/down monitoring to provide deep insights into network performance. By analyzing metrics such as latency, throughput, and packet loss across the entire infrastructure, it can identify performance bottlenecks and predict potential capacity issues before they affect the user experience. This proactive approach to network management ensures that services remain fast and reliable, consistently meeting demanding SLAs.
Proactive Security Posture with AI
While not a replacement for dedicated security tools, AIOps contributes to a stronger security posture. Its anomaly detection capabilities can identify unusual patterns of behavior that may indicate a security breach, such as unexpected data transfers or configuration changes. By flagging deviations from the norm, AIOps provides an early warning system that enables security teams to investigate and neutralize threats before they cause significant damage.
Head-to-Head Comparison: AIOps vs. Traditional NOC
When placed side by side, the differences between the two models become stark. AIOps represents a fundamental upgrade across key operational performance, efficiency, and business-impact metrics.
Operational Efficiency and Cost
A traditional NOC is labor-intensive, requiring large teams of engineers to monitor screens and investigate alerts 24/7 manually. This model incurs high staffing costs and suffers from inefficiencies tied to manual processes. AIOps introduces massive operational leverage through automation. Automating alert correlation, RCA, and ticketing reduces manual workload, allowing smaller teams to manage larger, more complex environments. This directly lowers operational costs and improves overall efficiency.
Incident Management and Resolution Speed
Incident management in a traditional NOC is a linear, often slow process. In contrast, AIOps radically accelerates the entire lifecycle. It detects incidents faster through anomaly detection, diagnoses them instantly with automated root cause analysis, and can even trigger automated remediation workflows. The result is a dramatic reduction in Mean Time to Resolution (MTTR), minimizing downtime duration and impact.
Visibility and Proactive Capabilities
A traditional NOC often operates with fragmented visibility, relying on a patchwork of siloed monitoring tools. This makes it difficult to understand cross-domain dependencies. AIOps provides a single, unified view of the entire IT infrastructure through comprehensive data discovery and aggregation. More importantly, it uses this visibility to enable proactive operations, predicting issues like disk space shortages or performance degradation before they cause an outage.
Scalability and Complexity Management
The human-centric model of a traditional NOC cannot scale to meet the complexity of modern IT. As new services and technologies are added, engineers’ cognitive load becomes unsustainable. AIOps is designed for scale and complexity. Its Machine Learning models can process data from millions of sources simultaneously, adapting dynamically as the environment changes. This allows organizations to grow and innovate without their operational capabilities becoming a bottleneck.
Business Impact and User Experience
Ultimately, the goal of IT operations is to support the business. The reactive nature of a traditional NOC means the business often feels the pain of IT issues through downtime and poor performance, resulting in negative customer impact. By minimizing downtime, proactively resolving performance issues, and ensuring service reliability, AIOps directly enhances the user experience. This strengthens customer satisfaction, protects revenue streams, and enables the business to operate with confidence.
The Strategic Imperative: AIOps as the Engine for IT Transformation
Adopting AIOps is more than a technical upgrade; it is a strategic decision that fundamentally alters the role and value of IT operations within an organization. It’s about evolving from a cost center focused on keeping the lights on to a strategic enabler of business innovation and growth.
Shifting from Reactive to Proactive: A Cultural and Operational Shift
The move to AIOps necessitates a cultural shift away from the “break-fix” mentality. It requires teams to trust the insights generated by AI and to focus their efforts on proactive optimization and long-term improvements rather than constant firefighting. This transition empowers teams to prevent outages, improve service quality, and contribute more strategically to business goals.
The Evolving Role of the NOC Engineer: From Firefighter to Strategist
AIOps does not replace NOC engineers; it elevates them. By automating the tedious, repetitive tasks of alert monitoring and initial diagnosis, AIOps frees up highly skilled human talent. Engineers can transition from being tactical firefighters to strategic problem-solvers. Their focus shifts to analyzing performance trends, optimizing system architecture, improving automation playbooks, and driving continuous service improvement initiatives.
AIOps and the Modern IT Ecosystem
AIOps is a foundational component of modern IT practices like DevOps and SRE (Site Reliability Engineering). It provides shared visibility and automated feedback loops necessary to support rapid development cycles and ensure service reliability in production. By integrating with ITSM and other enterprise systems, AIOps becomes the intelligent core that connects and optimizes the entire IT ecosystem.
Future-Proofing IT Operations with Emerging AI
The field of AI is evolving rapidly. By building a foundation on an AIOps platform, organizations are not just solving today’s problems but are also positioning themselves to leverage future advancements. As AI technologies like generative AI become more sophisticated, they will be integrated into AIOps platforms to offer even more advanced capabilities, such as generating human-readable incident summaries or suggesting complex remediation code.
Implementing AIOps: A Roadmap for Successful Transformation
Transitioning from a traditional NOC to an AIOps-driven model is a journey that requires careful planning and a phased approach. A successful implementation focuses on delivering value quickly while building a foundation for long-term success.
Assessing Your Current State and Defining Objectives
The first step is to conduct a thorough assessment of your current IT operations. Identify the biggest pain points—is it alert fatigue, slow RCA, or frequent outages? Based on this assessment, define clear, measurable objectives for your AIOps initiative.
Start with a high-impact use case, such as intelligent alert correlation, to demonstrate value and build momentum. By aligning the implementation with tangible business goals, you ensure that the transformation delivers real, measurable results.
